前言
MapReduce是用java寫的(不會寫java的可以用拉丁豬,but我不會拉丁豬),所以使用eclipse搭配hadoop-eclipse-plugin來開發Hadoop的MapReduce程式很方便,寫完後可以在eclipse中debug還可以直接看到程式產出的output,以下就是簡單的幾個範例。雖然Hadoop框架是用java實作,MapReduce應用程式不一定要用java來寫,可以利用Hadoop streaming跟Hadoop pipes這兩個工具把其他語言套到MapReduce中。(依舊是那個but~~這兩個我都不會)
官網上入門的範例是wordcount,以下是Hadoop in action中的範例,書中的程式碼是0.20之前的寫法,以下我就把程式碼改寫成1.0.3的版本。以下是MapReduce的小小簡介,再深入的底層原理我也不懂。
凡治眾如治寡,分數是也。鬥眾如鬥寡,形名是也。《孫子》
MapReduce的原理對應到演算法就是"Divide and Conquer"(分治法)。
MapReduce採用"分而治之"的思想,把對大規模數據的操作,分發給一個主節點管理下的各分節點來共同完成,然後通過整合各分節點的中間結果,得到最終結果。簡單的說,MapReduce就是"任務的分解與結果的匯整"。
上述的處理過程被MapReduce分為兩個函數,map跟reduece。map,負責把工作(job)分解成很多任務(task);reduce,負責把分解後多任務(task)處理的結果匯總起來。
將一個大問題,分割成許多小問題;將這些小問題解決之後,原本的大問題也就解決了。如果小問題還是很難,那就再切成更小的問題就行了。分割問題、各個擊破,這就是"Divide and Conquer"的精神。
MapReduce介紹
這位網誌的主人還有寫了其他相關工具的介紹, 也是很不錯的, 有空可以去逛逛
環境
主戰機是windows7專業版64位元,vmplayer裝ubuntu12.04 桌面板 64位元。在下大膽的假設看到這邊的人已經照著之前的網誌裝好環境了。
Eclipse是3.6 SR2。
工具包
載點
以上連結中有一個cite75_99.zip下載後把裡面的txt檔放到你喜歡的目錄底下。這一個美國專利引用次數的紀錄檔,有16,500,000多筆資料,第一欄是專利代號,第二欄是第一欄的專利被哪一個專利引用過。PS:先把第一行"CITING","CITED"刪掉吧,不然等一下第三個MapReduce程式會出錯,找出bug後會再補上去的。
實作
假設各看官都已經成功啟動Hadoop也照著之前的網誌裝好eclipse了。
[步驟一]
先建立一個HDFS的目錄,hadoop dfs -mkdir /hduser/cite/input,再把cite75_99.txt上傳到HDFS目錄中,hadoop dfs -put hadoopbook/cite/data/cite75_99.txt /hduser/cite/input。(這邊有點久,要等一下,因為會切成4個block,每一個block會copy3份)。完成後確認一下檔案,hadoop fsck /hduser/cite/input/cite75_99.txt -files -blocks -locations

上傳好後到eclipse看看,檔案是不是放在你要的路徑中

[步驟二]
功力厲害的是可以用nano或是三小碗糕編輯器等等來寫程式,像我這種沒IDE就不會寫程式的就要借用eclipse了。依照個人口味啦,我是習慣寫好MapReduce程式後沒有錯誤的紅叉叉,把java檔複製到我要的路徑下,再把.java編譯成jar檔。先建立一個HdPrj請見下圖。
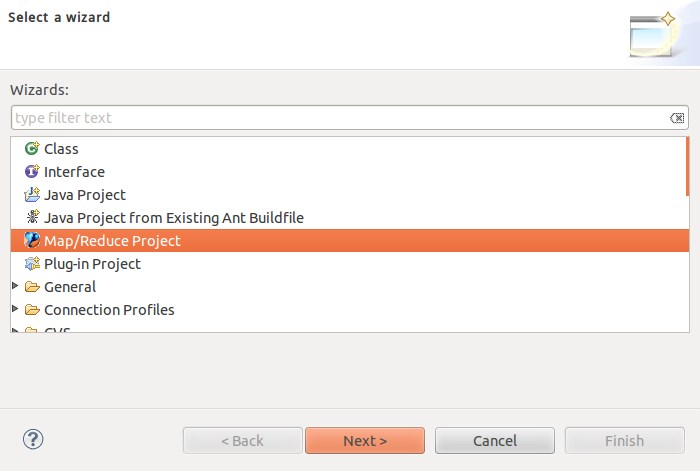

按下右邊的"Configure Hadoop install directory"
進來後,填入你hadoop的安裝資料夾路徑,/home/pablo/hadoop-1.0.3
OK-->finish,這樣就好了。

接下來在HdPrj按右鍵,Build path-->Coufigure build path..-->頁籤切換到Libraries path

有三個東西要改,hadoop-ant-1.0.3.jar,hadoop-core-1.0.3.jar,hadoop-tools-1.0.3.jar的source attachment跟Javadoc location。從ant開始,剩下兩個依樣畫葫蘆,滑鼠點下Source attachment再點Edit。

按照以下的畫面修改

core跟tools的分別修改成(千萬不要照我的路徑寫,要按照自己的路徑><)
/home/pablo/hadoop-1.0.3/src/core
/home/pablo/hadoop-1.0.3/src/tools
以上三個的Javadoc location都是file:/home/pablo/hadoop-1.0.3/docs/api/

[步驟三]
稍微說明一下MapReduce架構。MapReduce任务過程分成兩個處理階段:map 階段 和reduce階段。每個階段都以key/value對作為輸入及輸出,並由開發人員選擇他們的類型。開發人員還需要定義兩個class(書裡面寫函數):map和reduce。今天是2012/09/03話說Hadoop 2.0 Alpha已經發佈了。舊的api不知道還有沒有留著,我想應該是有啦,我是喜歡用新的寫法,以下是新舊(舊的是指0.2之前的)兩種不同的寫法比較。
舊API寫法:
public class YouClass extends Configured implements Tool { public static class MapClass extends MapReduceBase implements Mapper<Text, Text,Text, Text> {
public void map(Text key, Text, value,OutputCollector<Text, Text> output,Reporter reporter) throws IOException {
.............
.............
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable value,OutputCollector<Text, Text> output,Reporter reporter)throws IOException {
.............
public static class Reduce extends MapReduceBase implements Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable value,OutputCollector<Text, Text> output,Reporter reporter)throws IOException {
.............
}
}
public int run(String[] args) throws Exception {
...............
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new YouClass(), args);
System.exit(res);
}
}
public int run(String[] args) throws Exception {
...............
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new YouClass(), args);
System.exit(res);
}
}
新API寫法:
public class YouClass extends Configured implements Tool {
public static class MapClass extends Mapper<Text, Text, Text, Text> {
public void map( Text key, Text value, Context context) throws IOException, InterruptedException {
..........
新API寫法:
public class YouClass extends Configured implements Tool {
public static class MapClass extends Mapper<Text, Text, Text, Text> {
public void map( Text key, Text value, Context context) throws IOException, InterruptedException {
..........
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
public void reduce( Text key, Iterable value, Context context) throws IOException, InterruptedException {
..........
}
}
public int run(String[] args) throws Exception {
...............
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new YouClass(), args);
}
public int run(String[] args) throws Exception {
...............
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new YouClass(), args);
System.exit(res);
}
}
}
新舊API主要的差異有以下幾點:
1.新版的Map跟Reduce傾向於使用抽象類別,而不是舊版的interface。
2.新版的API是放在org.apache.hadoop.mapreduce中舊版的是放
在org.apache.hadoop.mapred中,撰寫時版本一定要統一。
3.新版的API用Context代替了舊版的OutputCollector跟Report。
輸出key/value時不再是outputCollector.collect()而是context.write()。
4.新版執行作業是用job舊版是用JobClient。
5.新版用Configuration來改變配置,舊版是用JobConf。
6.多了可以拋出InterruptedException而非單一的IOException。
7.reduce()方法中用Iterable代替Iterator,更容易使用foreach語法。
8.map產出的檔案名稱改成part-m-00000, reduce產出的檔案名稱改成part-r-00000(從零開始編號)
以上八點是我目前可以想到的,以後發現有別的差異再補上。
OK,現在就來開始新增一個class,MyJob。
我們把以上的code複製貼到eclipse的MyJob.java中,args[0]跟args[1]分別改成"/hduser/cite/input"以及"/hduser/cite/output"。(這樣的做法是把參數hardcode了)
PS:args[0]是要分析的檔案資料輸入路徑,剛剛已經放了一個cite75_99.txt了。
args[1]是檔案分析完產生最後結果的檔案輸出路徑。切記不能先產生這路徑,不然會發生Exception。
args[0]跟args[1]是在terminal中指令傳入的兩個參數,在eclipse中可以這樣搞。

改完後執行run as -- > run on hadoop,選擇你的hadoop location,你就會看到console就開始跑了。會看到map從0%一直跑到100%,再接著reduce從0%一直跑到100%。完成後就會產生一個/hduser/cite/output資料夾裡面會有兩個檔案。見下圖。



你要在eclipse裡面打開part-r-00000來看結果也可以,到terminal中看也可以,我是用後者。hadoop dfs -cat /hduser/cite/output/part-r-00000輸出的檔案很長我就不執行截圖了,跑完天都黑了。
*****************************************************************
16,500,000筆資料在大象的世界裡面應該算"奈米級"的數量吧,不過令我很驚豔的是在VM中跑大象兩分鐘就統計完了,挺不賴的。遙想當年有位前輩舉了最生活化的例子就是統計投票數,每個投開票所統計完票數後(把data放在local端計算)再傳回給大選中心,這樣的計數效率是最好的。
*****************************************************************
以下我用terminal編譯來執行一次。我是用我自己的習慣來決定存放.java .class .jar的路徑,不一定要跟我一樣。
我把.java放在/home/pablo/hadoopbook/cite/java/MyJob/MyJob.java
編譯過的.class放在/home/pablo/hadoopbook/cite/class/MyJob/,包起來的.jar我放在hadoopJar中。以下每一行是一行指令,請記得把輸入輸出的路徑改回args[0]以及args[1]再把/hduser/cite/output這資料夾先刪除,不然看到以下的錯誤訊息。這是hadoop安全機制的一種。
Exception in thread "main" org.apache.Hadoop.mapred.FileAlreadyExistsException: Output directory output already exists
這目錄在執行工作前應該不存在的, 否則Hadoop將會回報錯誤以及拒絕執行工作, 這措施是為了預防資料漏失(當一個需要執行長時間的任務被另一個任務覆蓋是很討厭的事情)
hadoop dfs -rmr /hduser/cite/output
javac -classpath hadoop-1.0.3/hadoop-core-1.0.3.jar -d hadoopbooks/cite/class/MyJob/ hadoopbooks/cite/java/MyJob/MyJob.java
jar -cvf hadoopJar/MyJob.jar -C hadoopbooks/cite/class/MyJob/ .
hadoop jar hadoopJar/MyJob.jar MyJob /hduser/cite/input /hduser/cite/output
結果會跟用ecplise跑出來一樣,terminal在跑的時候,也可以到web管理介面去看Map跟Reduce執行的結果跟進度。
http://namenode的ip:50030。(只有用terminal編譯執行jar檔web管理介面才有資訊可以看,用eclipse執行沒有)
(我的是http://10.0.3.1:50030)






這程式是統計每個專利有被那些專利引用,下面第二個程式是指顯示那些專利被引用過幾次,而不是列出一堆來。
新增一個class MyJob2.java
我就不用eclipse裡面執行了,我習慣在terminal中編譯執行。以下應該可以看出我的存放路徑XD。
javac -classpath hadoop-1.0.3/hadoop-core-1.0.3.jar -d hadoopbooks/cite/class/MyJob2/ hadoopbooks/cite/java/MyJob2/MyJob2.java
jar -cvf hadoopJar/MyJob2.jar -C hadoopbooks/cite/class/MyJob2/ .
hadoop jar hadoopJar/MyJob2.jar MyJob2 /hduser/cite/input /hduser/cite/output1
過程跟結果就不多說了,自己執行就知道了。

有時不一定要對上傳的檔案做分析,也可以使用產出的檔案當作MapReduce的輸入檔案,以下的CitationHistogram.java就是一個例子。這程式是要把被引過的專利次數畫成一個XY軸的統計圖表,不過程式只有產出數字沒有產出圖表,因為我也不會XD,會的好心人來教教我吧。
新增一個CitationHistogram.java
javac -classpath hadoop-1.0.3/hadoop-core-1.0.3.jar -d hadoopbooks/cite/class/ CitationHistogram/ hadoopbooks/cite/java/ CitationHistogram / CitationHistogram .java
jar -cvf hadoopJar/ CitationHistogram .jar -C hadoopbooks/cite/class/ CitationHistogram / .
hadoop jar hadoopJar/ CitationHistogram .jar CitationHistogram /hduser/cite/output1 /hduser/cite/output2
程式指令都有了,自己執行吧。
三個都執行後你的HDFS目錄應該會長得像這樣子。
hadoop dfs -ls /hduser/cite

到http://10.0.3.1:50030去看,應該會有三個Completed Jobs(MyJob2我自己多做了一次)

以上,OVER。
新舊API主要的差異有以下幾點:
1.新版的Map跟Reduce傾向於使用抽象類別,而不是舊版的interface。
2.新版的API是放在org.apache.hadoop.mapreduce中舊版的是放
在org.apache.hadoop.mapred中,撰寫時版本一定要統一。
3.新版的API用Context代替了舊版的OutputCollector跟Report。
輸出key/value時不再是outputCollector.collect()而是context.write()。
4.新版執行作業是用job舊版是用JobClient。
5.新版用Configuration來改變配置,舊版是用JobConf。
6.多了可以拋出InterruptedException而非單一的IOException。
7.reduce()方法中用Iterable代替Iterator,更容易使用foreach語法。
8.map產出的檔案名稱改成part-m-00000, reduce產出的檔案名稱改成part-r-00000(從零開始編號)
以上八點是我目前可以想到的,以後發現有別的差異再補上。
OK,現在就來開始新增一個class,MyJob。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MyJob extends Configured implements Tool{
public static class MapClass extends Mapper<LongWritable, Text, Text, Text> {
public void map (LongWritable key, Text value, Context context) throws IOException , InterruptedException {
String[] citation = value.toString().split(",");
context.write(new Text(citation[0]), new Text(citation[1]));
}
}
public static class ReduceClass extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String csv = "";
for (Text val : values) {
if (csv.length() > 0) {
csv += ",";
}
csv += val.toString();
}
context.write(key, new Text(csv));
}
}
public int run(String [] args) throws IOException , InterruptedException, ClassNotFoundException {
Configuration conf = getConf();
Job job = new Job(conf , "MyJob");
job.setJarByClass(MyJob.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MapClass.class);
job.setReducerClass(ReduceClass.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new MyJob(), args);
System.exit(res);
}
}
[步驟四]
寫一個MapReduce有兩種方式來執行,第一:在文字檔中寫好編譯成jar再用hadoop jar來執行,第二:在eclipse中寫好後,args[0]跟args[1]寫死路徑然後run as-->run on hadoop。先從第二種講起比較簡單。我們把以上的code複製貼到eclipse的MyJob.java中,args[0]跟args[1]分別改成"/hduser/cite/input"以及"/hduser/cite/output"。(這樣的做法是把參數hardcode了)
PS:args[0]是要分析的檔案資料輸入路徑,剛剛已經放了一個cite75_99.txt了。
args[1]是檔案分析完產生最後結果的檔案輸出路徑。切記不能先產生這路徑,不然會發生Exception。
args[0]跟args[1]是在terminal中指令傳入的兩個參數,在eclipse中可以這樣搞。

改完後執行run as -- > run on hadoop,選擇你的hadoop location,你就會看到console就開始跑了。會看到map從0%一直跑到100%,再接著reduce從0%一直跑到100%。完成後就會產生一個/hduser/cite/output資料夾裡面會有兩個檔案。見下圖。



你要在eclipse裡面打開part-r-00000來看結果也可以,到terminal中看也可以,我是用後者。hadoop dfs -cat /hduser/cite/output/part-r-00000輸出的檔案很長我就不執行截圖了,跑完天都黑了。
*****************************************************************
16,500,000筆資料在大象的世界裡面應該算"奈米級"的數量吧,不過令我很驚豔的是在VM中跑大象兩分鐘就統計完了,挺不賴的。遙想當年有位前輩舉了最生活化的例子就是統計投票數,每個投開票所統計完票數後(把data放在local端計算)再傳回給大選中心,這樣的計數效率是最好的。
*****************************************************************
以下我用terminal編譯來執行一次。我是用我自己的習慣來決定存放.java .class .jar的路徑,不一定要跟我一樣。
我把.java放在/home/pablo/hadoopbook/cite/java/MyJob/MyJob.java
編譯過的.class放在/home/pablo/hadoopbook/cite/class/MyJob/,包起來的.jar我放在hadoopJar中。以下每一行是一行指令,請記得把輸入輸出的路徑改回args[0]以及args[1]再把/hduser/cite/output這資料夾先刪除,不然看到以下的錯誤訊息。這是hadoop安全機制的一種。
Exception in thread "main" org.apache.Hadoop.mapred.FileAlreadyExistsException: Output directory output already exists
這目錄在執行工作前應該不存在的, 否則Hadoop將會回報錯誤以及拒絕執行工作, 這措施是為了預防資料漏失(當一個需要執行長時間的任務被另一個任務覆蓋是很討厭的事情)
hadoop dfs -rmr /hduser/cite/output
javac -classpath hadoop-1.0.3/hadoop-core-1.0.3.jar -d hadoopbooks/cite/class/MyJob/ hadoopbooks/cite/java/MyJob/MyJob.java
jar -cvf hadoopJar/MyJob.jar -C hadoopbooks/cite/class/MyJob/ .
hadoop jar hadoopJar/MyJob.jar MyJob /hduser/cite/input /hduser/cite/output
結果會跟用ecplise跑出來一樣,terminal在跑的時候,也可以到web管理介面去看Map跟Reduce執行的結果跟進度。
http://namenode的ip:50030。(只有用terminal編譯執行jar檔web管理介面才有資訊可以看,用eclipse執行沒有)
(我的是http://10.0.3.1:50030)






這程式是統計每個專利有被那些專利引用,下面第二個程式是指顯示那些專利被引用過幾次,而不是列出一堆來。
新增一個class MyJob2.java
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MyJob2 extends Configured implements Tool{
public static class MapClass extends Mapper<LongWritable, Text, Text, Text> {
public void map (LongWritable key, Text value, Context context) throws IOException , InterruptedException {
String[] citation = value.toString().split(",");
context.write(new Text(citation[0]), new Text(citation[1]));
}
}
public static class ReduceClass extends Reducer<Text, Text, Text, LongWritable> {
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int count = 0 ;
for (Text val:values) {
count++;
}
context.write(key, new LongWritable(count));
}
}
public int run(String [] args) throws Exception {
Configuration conf = getConf();
Job job = new Job(conf , "MyJob2");
job.setJarByClass(MyJob2.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MapClass.class);
job.setReducerClass(ReduceClass.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new MyJob2(), args);
System.exit(res);
}
}
我就不用eclipse裡面執行了,我習慣在terminal中編譯執行。以下應該可以看出我的存放路徑XD。
javac -classpath hadoop-1.0.3/hadoop-core-1.0.3.jar -d hadoopbooks/cite/class/MyJob2/ hadoopbooks/cite/java/MyJob2/MyJob2.java
jar -cvf hadoopJar/MyJob2.jar -C hadoopbooks/cite/class/MyJob2/ .
hadoop jar hadoopJar/MyJob2.jar MyJob2 /hduser/cite/input /hduser/cite/output1
過程跟結果就不多說了,自己執行就知道了。

有時不一定要對上傳的檔案做分析,也可以使用產出的檔案當作MapReduce的輸入檔案,以下的CitationHistogram.java就是一個例子。這程式是要把被引過的專利次數畫成一個XY軸的統計圖表,不過程式只有產出數字沒有產出圖表,因為我也不會XD,會的好心人來教教我吧。
新增一個CitationHistogram.java
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class CitationHistogram extends Configured implements Tool {
public static class MapClass extends Mapper<Text, Text, IntWritable, IntWritable> {
private final static IntWritable uno = new IntWritable(1);
private IntWritable citationCount = new IntWritable();
@Override
public void map(Text key, Text value, Context context) throws IOException, InterruptedException {
if (!"".equals(value)) {
citationCount.set(Integer.parseInt(value.toString()));
context.write(citationCount, uno);
}
}
}
public static class ReduceClass extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
@Override
public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException , InterruptedException {
int count = 0;
for (IntWritable val : values) {
count += val.get();
}
context.write(key, new IntWritable(count));
}
}
public int run(String [] args) throws Exception {
Configuration conf = getConf();
Job job = new Job(conf , "CitationHistogram");
job.setJarByClass(CitationHistogram.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[0]));
job.setMapperClass(MapClass.class);
job.setReducerClass(ReduceClass.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new CitationHistogram(), args);
System.exit(res);
}
}
javac -classpath hadoop-1.0.3/hadoop-core-1.0.3.jar -d hadoopbooks/cite/class/ CitationHistogram/ hadoopbooks/cite/java/ CitationHistogram / CitationHistogram .java
jar -cvf hadoopJar/ CitationHistogram .jar -C hadoopbooks/cite/class/ CitationHistogram / .
hadoop jar hadoopJar/ CitationHistogram .jar CitationHistogram /hduser/cite/output1 /hduser/cite/output2
程式指令都有了,自己執行吧。
三個都執行後你的HDFS目錄應該會長得像這樣子。
hadoop dfs -ls /hduser/cite

到http://10.0.3.1:50030去看,應該會有三個Completed Jobs(MyJob2我自己多做了一次)

以上,OVER。
請問,什麼是拉丁豬阿
回覆刪除